LaneIQ
A reinforcement learning project for lane-level driving decisions, short-horizon world modeling, and V2X-informed traffic awareness.
Project Overview
LaneIQ is a small driving research project built around one core task: learning when to stay in lane, stop, or merge in traffic. The agent trains in a three-lane simulator with moving cars and receives local traffic features plus V2X-style lane risk scores.
That interaction data is then reused to train a one-step world model, which predicts what happens next for a given state and action.
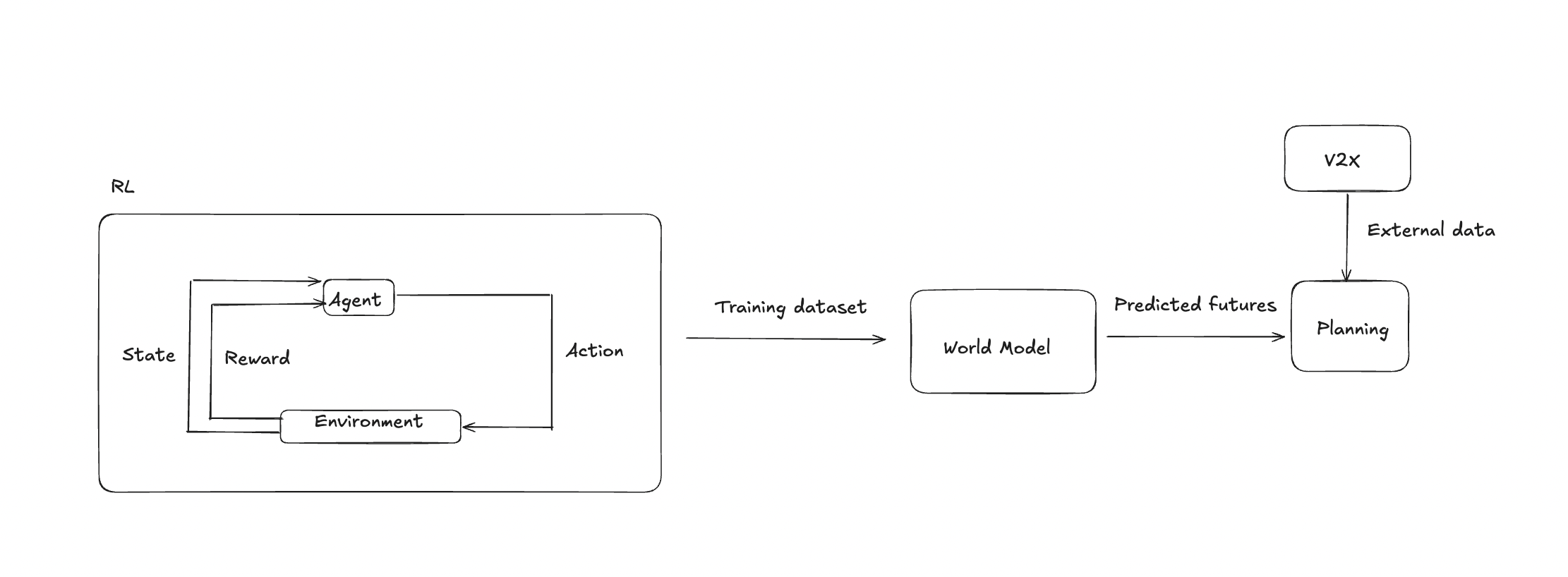
Policy and Environment Design
The reinforcement learning component is framed as lane-level tactical decision-making in a three-lane traffic simulator. The agent receives a compact local state, chooses from discrete lane-plus-motion actions, and is optimized to balance progress, safety, and merge discipline.
Observation Space
Action Space
Reward Design
Learning Objective
Environment Generation
World Model and Training Data
The predictive model is trained on transition tuples collected from policy-environment interaction. Its role is to approximate one-step dynamics, reward, and episode completion so that candidate action sequences can be evaluated before execution.
Training Data Schema
Sample Transition
Optimization Targets
Showcase
The sections below are generated from saved artifacts rather than live execution. They show one fixed-sample policy rollout and one imagination example in which the world model predicts short-horizon futures and those predictions are compared against the real simulator.